Startup for analyzing and managing Big Software
Background

Customer Request
Challenges & Solutions
Challenges
Simplement the fastest possible data collection by code components
The challenge was collecting data on open-source components from platforms like GitHub and NPM. Codescoop's parsers were too slow to collect metadata quickly enough, prompting the search for better solutions to boost service productivity.
The need to store more than 100 million time-series with fast search in the database
Regular databases like MongoDB couldn’t handle storing and quickly searching 100 million components. This required finding and implementing more specialized solutions for time series data storage.
Optimization of work with code components when finalizing Big Software
Finding relevant code points from various open-source components took too long for Codescoop clients. An automation tool was needed to optimize the process and enable flexible searching of components across all open sources.
Solutions
Integration of ORT into Software Intelligence system
The tool automated the search for license conflicts between open-source components and requirements. This sped up software releases, minimized license compliance risks, and saved corporate customers a significant portion of their budget.
Implementation of GBT for storing a time series of parsing results over 3 years of the product life cycle
We used daily time series for the last 3 years to store component development history, totaling 100 million series. To speed up data processing and improve performance, we implemented Google Bigtable, then switched to HBase.
Search and filtering system for Big Software code components
FTL implemented Elasticsearch for scalable, multi-threaded searches based on various metrics and component characteristics. This allowed developers to quickly find relevant elements for further work during software product improvement.

project facts

main features
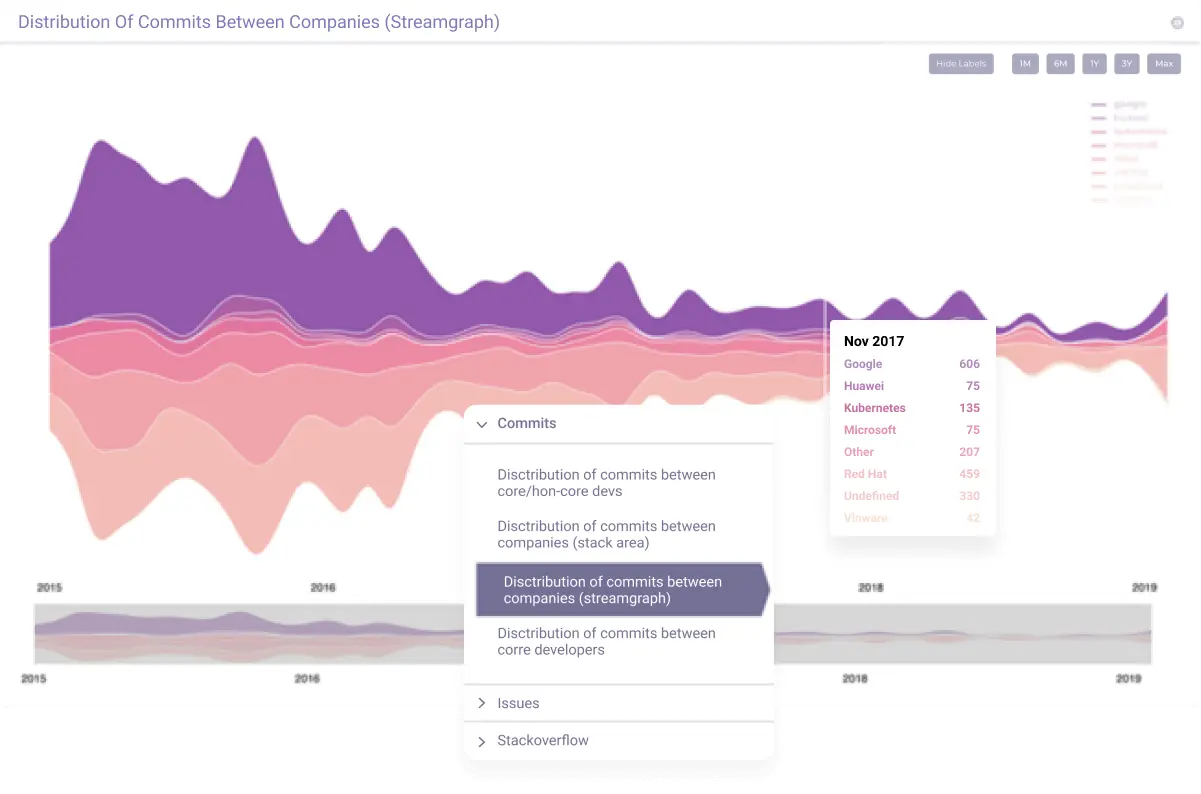
Development of convenient UI/UX system
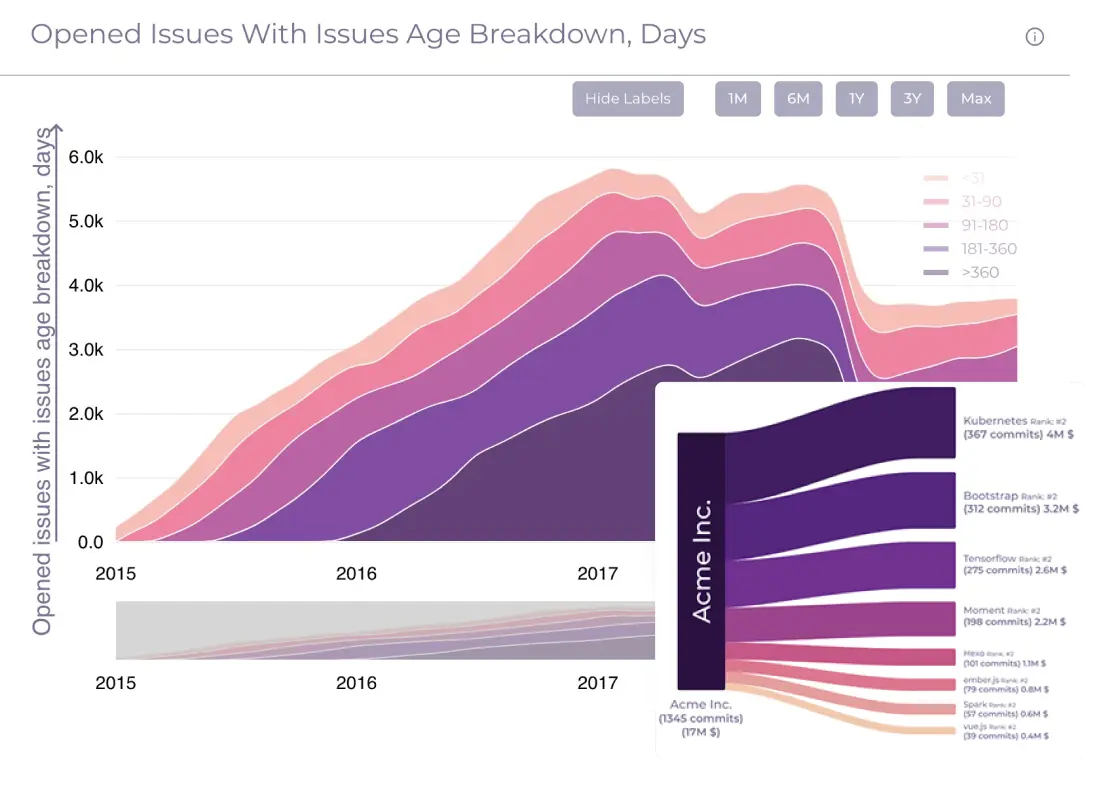
The project team created a unique visualization. Thanks to it, even in the early stages of the software product life cycle, you can get a comprehensive analysis of the Big Software technical stack in diagrams and metrics. This saves a significant portion of the budget and time for managing critical operations, fixing failures, and implementing changes in the later stages of the product life cycle.
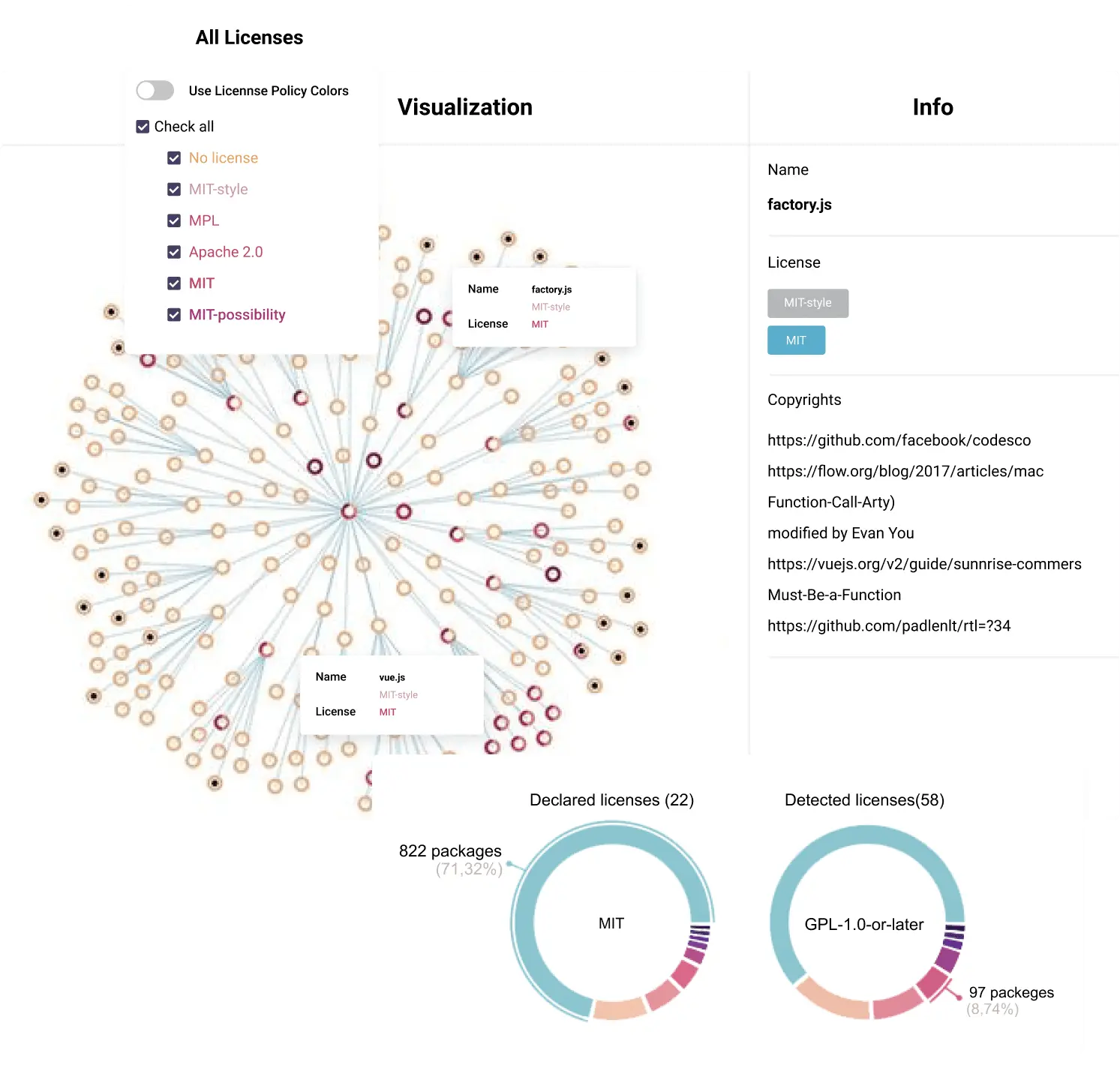
Definition of key metrics and clustering of components into groups
Software Intelligence not only includes cross-system data collection algorithms but also allows you to analyze vulnerabilities and propose solutions to improve the software product. The Codescoop team, together with FTL specialists, developed a unique tool based on Python, machine learning, and artificial intelligence methods to create predictions for the development of software components in the time and technical plane. With its help, Big Software developers can make timely tactical and strategic decisions to improve and change the software product depending on the requirements.

Technologies used
